Testing whisper.cpp on android
This are notes taken down while testing out Whisper.cpp on an Amlogic A311D2 platform.
Whisper.cpp is an implementation of OpenAI’s automatic speech recognition(ASR) model using the ggml machine learning library. The project has an example for android which I’m going to play around with.
Clone the project
Using the github client to clone the repo:
$ gh repo clone ggerganov/whisper.cpp
Cloning into 'whisper.cpp'...
remote: Enumerating objects: 14379, done.
remote: Counting objects: 100% (68/68), done.
remote: Compressing objects: 100% (32/32), done.
remote: Total 14379 (delta 41), reused 36 (delta 35), pack-reused 14311 (from 2)
Receiving objects: 100% (14379/14379), 18.07 MiB | 3.69 MiB/s, done.
Resolving deltas: 100% (9834/9834), done.
We’re going to try running the whisper.android example. This is written using Kotlin. There is another example i.e. whisper.android.java which is written in Java.
$ pwd
/home/XXX/XXX/XXX/XXX/XX/whisper.cpp
$ ls -d examples/whisper.android*
examples/whisper.android examples/whisper.android.java
Opening Using Android Studio
Open android studio and open existing project

On opening android studio syncs the gradle project
Downloading a model
The whisper.cpp/README.md explains how to download a model. Let’s download the tiny.en model:
$ sh ./models/download-ggml-model.sh tiny.en
Downloading ggml model tiny.en from 'https://huggingface.co/ggerganov/whisper.cpp' ...
ggml-tiny.en.bin 100%[=================================================================================================>] 74.10M 11.6MB/s in 7.0s
Done! Model 'tiny.en' saved in '/home/XXX/XXX/whisper.cpp/models/ggml-tiny.en.bin'
You can now use it like this:
$ ./build/bin/whisper-cli -m /home/XXX/XXX/whisper.cpp/models/ggml-tiny.en.bin -f samples/jfk.wav
Now as per the whisper.cpp/examples/whisper.android/README.md we have to copy this
to "app/src/main/assets/models.
$ mkdir -p examples/whisper.android/app/src/main/assets/models
$ cp models/ggml-tiny.en.bin examples/whisper.android/app/src/main/assets/models/.
Copy a sample
Next copy the sample:
$ mkdir -p examples/whisper.android/app/src/main/assets/samples
$ cp samples/jfk.wav examples/whisper.android/app/src/main/assets/samples/.
Change the active build variant
Go to Build > Select Build Variant and select release from the menu.
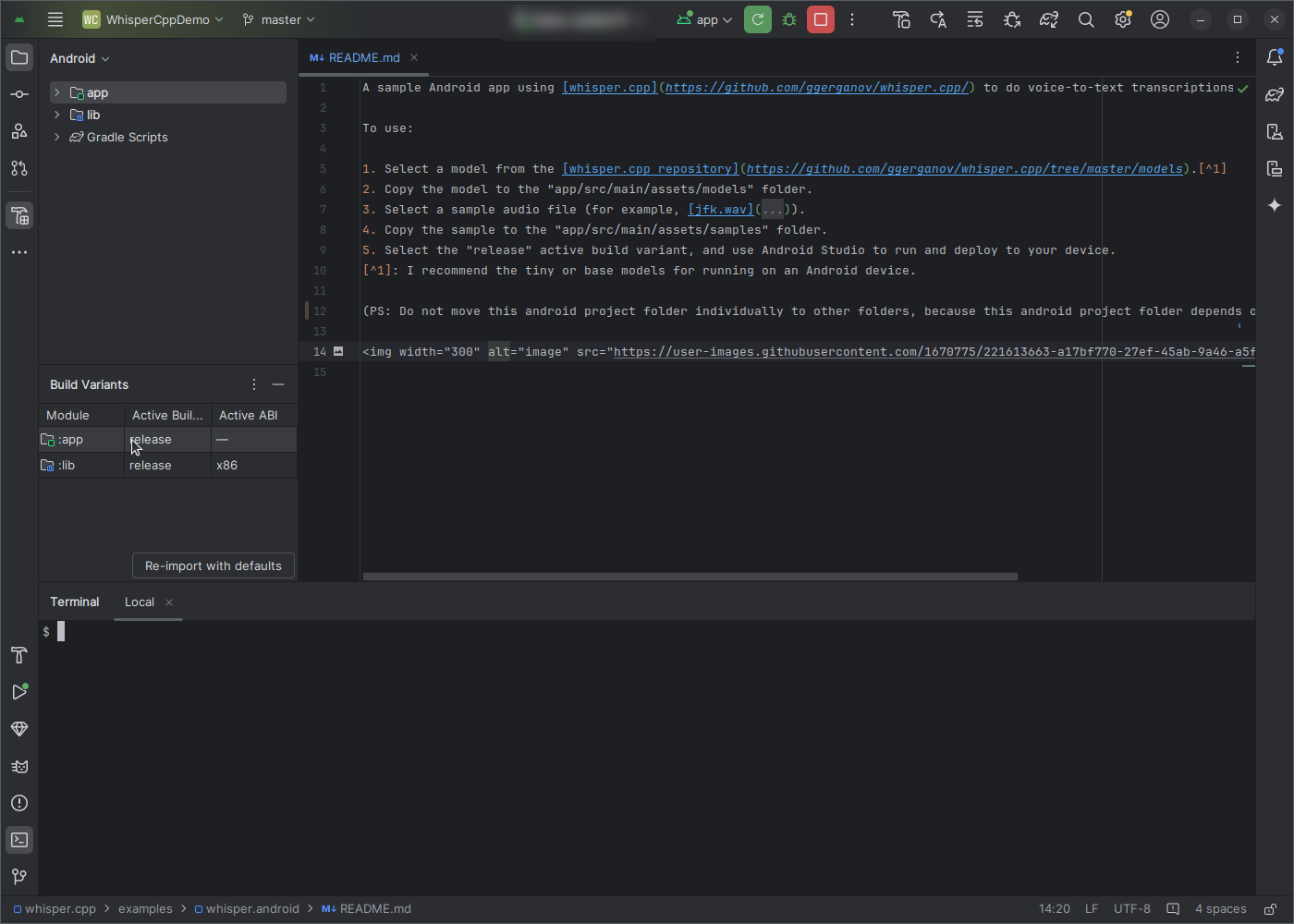
Run the app
Hit the play button to run the app. We get the following output on the display.

We can see the system information displayd. These are instruction set extensions and processor features used for optimizing and accelerating numerical, multimedia and computational tasks.
Deciphering the system info
AVX: A set of SIMD (Single Instruction Multiple Data) instructions introduced by Intel in 2011 (with Sandy Bridge processors). Optimizes floating-point and integer operations for applications like scientific computing, 3D modeling, and multimedia processing.
AVX2: An enhancement of AVX introduced with Intel’s Haswell architecture in 2013.
AVX512: A further extension introduced with Intel’s Skylake-X processors (2016).
FMA (Fused Multiply-Add): A specialized instruction that combines multiplication and addition into a single operation.
NEON: A SIMD extension for ARM processors.
ARM_FMA: ARM’s implementation of the Fused Multiply-Add operation.
FP16C (Floating-Point 16-bit Conversion): : Provides hardware acceleration for converting between half-precision (16-bit) and single-precision (32-bit) floating-point numbers.
FP16 (Half-Precision floating-point : A data type and associated operations for 16-bit floating-point numbers.
FP16_VA (FP16 Vector Arithmetic): Refers to vector arithmetic instructions specifically designed for FP16 operations.
Transcibe JFK Sample
We can see that the jfk.wav sample is copied and the ggml-tiny.en.bin model
is loaded. Now if we click on the Transcribe sample button it works and takes
4.3s to transcribe the 11s sample.

Since we’re running it on a TV device the scrollable text area gets clipped off
and we can’t read the text if we run it again. This behaviour can be changed in
MainScreen.kt in the MessageLog method by adding reverseScrolling = true
to the Modifier.verticalScroll argument.
@Composable
private fun MessageLog(log: String) {
SelectionContainer {
Text(modifier = Modifier.verticalScroll(rememberScrollState(), reverseScrolling = true), text = log)
}
}

This is much better!